Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
This brief tutorial provides a quick introduction to Big Data, MapReduce algorithm, and Hadoop Distributed File System
This tutorial has been prepared for professionals aspiring to learn the basics of Big Data Analytics using Hadoop Framework and become a Hadoop Developer. Software Professionals, Analytics Professionals, and ETL developers are the key beneficiaries of this course.
Before you start proceeding with this tutorial, we assume that you have prior exposure to Core Java, database concepts, and any of the Linux operating system flavors.
Due to the advent of new technologies, devices, and communication means for social networking sites, the amount of data produced by mankind is growing rapidly every year. The amount of data produced by us from the beginning of time till 2003 was 5 billion gigabytes. If you pile up the data in the form of disks it may fill an entire football field. The same amount was created in every two days in 2011, and in every ten minutes in 2013. This rate is still growing enormously. Though all this information produced is meaningful and can be useful when processed Hadoop Training in Mumbai, it is being neglected.
90% of the world’s data was generated in the last few years.
Big data means really a big data, it is a collection of large datasets that cannot be processed using traditional computing techniques. Big data is not merely a data, rather it has become a complete subject, which involves various tools, techniques, and frameworks
Big data involves the data produced by different devices and applications. Given below are some of the fields that come under the umbrella of Big Data.
· Black Box Data: It is a component of helicopter, airplanes, and jets, etc. It captures voices of the flight crew, recordings of microphones and earphones, and the performance information of the aircraft.
· Social Media Data: Social media such as Facebook and Twitter hold information and the views posted by millions of people across the globe.
· Stock Exchange Data: The stock exchange data holds information about the ‘buy’ and ‘sell’ decisions made on a share of different companies made by the customers.
· Power Grid Data: The power grid data holds information consumed by a particular node with respect to a base station.
· Transport Data: Transport data includes model, capacity, distance and availability of a vehicle.
· Search Engine Data: Search engines retrieve lots of data from different databases.

Thus Big Data includes huge volume, high velocity, and an extensible variety of data. The data in it will be of three types.
- Structured data: Relational data.
- Semi Structured data: XML data.
- Unstructured data: Word, PDF, Text, Media Logs.
Big data is really critical to our life and its emerging as one of the most important technologies in modern world. Follow are just few benefits which are very much known to all of us:
· Using the information kept in the social network like Facebook, the marketing agencies are learning about the response for their campaigns, promotions, and other advertising mediums.
· Using the information in the social media like preferences and product perception of their consumers, product companies and retail organizations are planning their production.
· Using the data regarding the previous medical history of patients, hospitals are providing better and quick service.
Big data technologies are important in providing more accurate analysis, which may lead to more concrete decision-making resulting in greater operational efficiencies, cost reductions, and reduced risks for the business.
To harness the power of big data, you would require an infrastructure that can manage and process huge volumes of structured and unstructured data in realtime and can protect data privacy and security.
There are various technologies in the market from different vendors including Amazon, IBM, Microsoft, etc., to handle big data. While looking into the technologies that handle big data, we examine the following two classes of technology:
Operational Big Data
This include systems like MongoDB that provide operational capabilities for real-time, interactive workloads where data is primarily captured and stored.
NoSQL Big Data systems are designed to take advantage of new cloud computing architectures that have emerged over the past decade to allow massive computations to be run inexpensively and efficiently. This makes operational big data workloads much easier to manage, cheaper, and faster to implement.
Some NoSQL systems can provide insights into patterns and trends based on real-time data with minimal coding and without the need for data scientists and additional infrastructure.
Analytical Big Data
This includes systems like Massively Parallel Processing (MPP) database systems and MapReduce that provide analytical capabilities for retrospective and complex analysis that may touch most or all of the data.
MapReduce provides a new method of analyzing data that is complementary to the capabilities provided by SQL, and a system based on MapReduce that can be scaled up from single servers to thousands of high and low end machines.
These two classes of technology are complementary and frequently deployed together.
Operational vs. Analytical Systems
|
Operational |
Analytical |
|
|
Latency |
1 ms - 100 ms |
1 min - 100 min |
|
Concurrency |
1000 - 100,000 |
1 - 10 |
|
Access Pattern |
Writes and Reads |
Reads |
|
Queries |
Selective |
Unselective |
|
Data Scope |
Operational |
Retrospective |
|
End User |
Customer |
Data Scientist |
|
Technology |
NoSQL |
MapReduce, MPP Database |
The major challenges associated with big data are as follows:
- Capturing data
- Curation
- Storage
- Searching
- Sharing
- Transfer
- Analysis
- Presentation
To fulfill the above challenges, organizations normally take the help of enterprise servers.
Traditional Approach
In this approach, an enterprise will have a computer to store and process big data. Here data will be stored in an RDBMS like Oracle Database, MS SQL Server or DB2 and sophisticated software can be written to interact with the database, process the required data and present it to the users for analysis purpose.
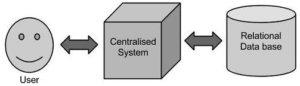
Limitation
This approach works well where we have less volume of data that can be accommodated by standard database servers, or up to the limit of the processor which is processing the data. But when it comes to dealing with huge amounts of data, it is really a tedious task to process such data through a traditional database server.
Google’s Solution
Google solved this problem using an algorithm called MapReduce. This algorithm divides the task into small parts and assigns those parts to many computers connected over the network, and collects the results to form the final result dataset.
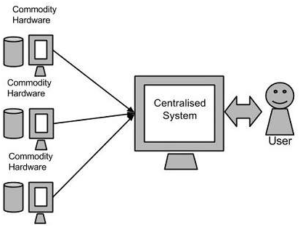
Above diagram shows various commodity hardware which could be single CPU machines or servers with higher capacity.
Doug Cutting, Mike Cafarella, and the team took the solution provided by Google and started an Open Source Project called HADOOP in 2005 and Doug named it after his son's toy elephant. Now Apache Hadoop is a registered trademark of the Apache Software Foundation.
Hadoop runs applications using the MapReduce algorithm, where the data is processed in parallel on different CPU nodes. In short, the Hadoop framework is capable enough to develop applications capable of running on clusters of computers and they could perform complete statistical analysis for huge amounts of data.

Hadoop is an Apache open source framework written in java that allows distributed processing of large datasets across clusters of computers using simple programming models. A Hadoop frame-worked application works in an environment that provides distributed storage and computation across clusters of computers. Hadoop is designed to scale up from single server to thousands of machines, each offering local computation and storage.
Hadoop Architecture
Hadoop framework includes following four modules:
- Hadoop Common: These are Java libraries and utilities required by other Hadoop modules. These libraries provide filesystem and OS level abstractions and contain the necessary Java files and scripts required to start Hadoop.
- Hadoop YARN: This is a framework for job scheduling and cluster resource management.
- Hadoop Distributed File System (HDFS
 ): A distributed file system that provides high-throughput access to application data.
): A distributed file system that provides high-throughput access to application data. - Hadoop MapReduce: This is a YARN-based system for parallel processing of large data sets.
We can use following diagram to depict these four components available in Hadoop framework.
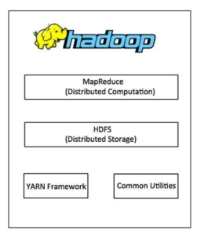
Since 2012, the term "Hadoop" often refers not just to the base modules mentioned above but also to the collection of additional software packages that can be installed on top of or alongside Hadoop, such as Apache Pig, Apache Hive, Apache HBase, Apache Spark etc
MapReduce
Hadoop MapReduce is a software framework for easily writing applications which process big amounts of data in parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
The term MapReduce actually refers to the following two different tasks that Hadoop programs perform:
- The Map Task: This is the first task, which takes input data and converts it into a set of data, where individual elements are broken down into tuples (key/value pairs).
- The Reduce Task: This task takes the output from a map task as input and combines those data tuples into a smaller set of tuples. The reduce task is always performed after the map task.
Typically both the input and the output are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
The MapReduce framework consists of a single master JobTracker and one slave TaskTracker per cluster node. The master is responsible for resource management, tracking resource consumption/availability and scheduling the jobs component tasks on the slaves, monitoring them and re-executing the failed tasks. The slaves TaskTracker execute the tasks as directed by the master and provide task status information to the master periodically.
The JobTracker is a single point of failure for the Hadoop MapReduce service which means if JobTracker goes down, all running jobs are halted.
Hadoop Distributed File System
Hadoop can work directly with any mountable distributed file system such as Local FS, HFTP FS, S3 FS, and others, but the most common file system used by Hadoop is the Hadoop Distributed File System (HDFS).
The Hadoop Distributed File System (HDFS) is based on the Google File System (GFS) and provides a distributed file system that is designed to run on large clusters (thousands of computers) of small computer machines in a reliable, fault-tolerant manner.
HDFS uses a master/slave architecture where master consists of a single NameNode that manages the file system metadata and one or more slave DataNodes that store the actual data.
A file in an HDFS namespace is split into several blocks and those blocks are stored in a set of DataNodes. The NameNode determines the mapping of blocks to the DataNodes. The DataNodes takes care of reading and writes operation with the file system. They also take care of block creation, deletion, and replication based on an instruction given by NameNode.
HDFS provides a shell like any other file system and a list of commands are available to interact with the file system. These shell commands will be covered in a separate chapter along with appropriate examples.
Stage 1
A user/application can submit a job to the Hadoop (a Hadoop job client) for required process by specifying the following items:
- The location of the input and output files in the distributed file system.
- The Java classes in the form of jar file containing the implementation of the map and reduce functions.
- The job configuration by setting different parameters specific to the job.
Stage 2
The Hadoop job client then submits the job (jar/executable etc) and configuration to the JobTracker which then assumes the responsibility of distributing the software/configuration to the slaves, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Stage 3
The TaskTrackers on different nodes execute the task as per MapReduce implementation and output of the reduce function is stored into the output files on the file system.
Advantages of Hadoop
- Hadoop framework allows the user to quickly write and test distributed systems. It is efficient, and it automatic distributes the data and work across the machines and in turn, utilizes the underlying parallelism of the CPU cores.
- Hadoop does not rely on hardware to provide fault-tolerance and high availability (FTHA), rather Hadoop library itself has been designed to detect and handle failures at the application layer.
- Servers can be added or removed from the cluster dynamically and Hadoop continues to operate without interruption.
- Another big advantage of Hadoop is that apart from being open source, it is compatible with all the platforms since it is Java based.
Hadoop History
As the World Wide Web grew in the late 1900s and early 2000s, search engines, and indexes were created to help locate relevant information amid the text-based content. In the early years, search results were returned by humans. But as the web grew from dozens to millions of pages, automation was needed. Web crawlers were created, many of university-led research projects and search engine start-ups took off (Yahoo, AltaVista, etc.)
Going beyond its original goal of searching millions (or billions) of web pages and returning relevant results, many organizations are looking to Hadoop as their next big data platform. Popular uses today include:
Low-cost storage and data archive
The modest cost of commodity hardware makes Hadoop useful for storing and combining data such as transactional, social media, sensor, machine, scientific, click streams, etc. The low-cost storage lets you keep information that is not deemed currently critical but that you might want to analyze later.
Sandbox for discovery and analysis
Because Hadoop was designed to deal with volumes of data in a variety of shapes and forms, it can run analytical algorithms. Big data analytics on Hadoop can help your organization operate more efficiently, uncover new opportunities and derive next-level competitive advantage. The sandbox approach provides an opportunity to innovate with minimal investment.
Data lake
Data lakes support storing data in its original or exact format. The goal is to offer a raw or unrefined view of data to data scientists and analysts for discovery and analytics. It helps them ask new or difficult questions without constraints. Data lakes are not a replacement for data warehouses. In fact, how to secure and govern data lakes is a huge topic for IT. They may rely on data federation techniques to create a logical data structures.
Complement your data warehouse
We're now seeing Hadoop beginning to sit beside data warehouse environments, as well as certain data sets being offloaded from the data warehouse into Hadoop or new types of data going directly to Hadoop. The end goal for every organization is to have a right platform for storing and processing data of different schema, formats, etc. to support different use cases that can be integrated at different levels.
IoT and Hadoop
Things in the IoT need to know what to communicate and when to act. At the core of the IoT is a streaming, always on torrent of data. Hadoop is often used as the data store for millions or billions of transactions. Massive storage and processing capabilities also allow you to use Hadoop as a sandbox for discovery and definition of patterns to be monitored for prescriptive instruction. You can then continuously improve these instructions, because Hadoop is constantly being updated with new data that doesn’t match previously defined patterns.
Building a recommendation engine in Hadoop
One of the most popular analytical uses by some of Hadoop's largest adopters is for web-based recommendation systems. Facebook – people you may know. LinkedIn – jobs you may be interested in. Netflix, eBay, Hulu – items you may want. These systems analyze huge amounts of data in real time to quickly predict preferences before customers leave the web page.
How: A recommender system can generate a user profile explicitly (by querying the user) and implicitly (by observing the user’s behavior) – then compares this profile to reference characteristics (observations from an entire community of users) to provide relevant recommendations. Petaa-Bytes provides a number of techniques and algorithms for creating a recommendation system, ranging from basic distance measures to matrix factorization and collaborative filtering – all of which can be done within Hadoop.
Currently, four core modules are included in the basic framework from the Apache Foundation:
Hadoop Common – the libraries and utilities used by other Hadoop modules.
Hadoop Distributed File System (HDFS) – the Java-based scalable system that stores data across multiple machines without prior organization.
YARN – (Yet Another Resource Negotiator) provides resource management for the processes running on Hadoop.
MapReduce – a parallel processing software framework. It is comprised of two steps. Map step is a master node that takes inputs and partitions them into smaller subproblems and then distributes them to worker nodes. After the map step has taken place, the master node takes the answers to all of the subproblems and combines them to produce output.
Other software components that can run on top of or alongside Hadoop and have achieved top-level Apache project status include:
|
Ambari |
A web interface for managing, configuring and testing Hadoop services and components. |
|
Cassandra |
A distributed database system. |
|
Flume |
Software that collects, aggregates and moves large amounts of streaming data into HDFS. |
|
HBase |
A nonrelational, distributed database that runs on top of Hadoop. HBase tables can serve as input and output for MapReduce jobs. |
|
HCatalog |
A table and storage management layer that helps users share and access data. |
|
Hive |
A data warehousing and SQL-like query language that presents data in the form of tables. Hive programming is similar to database programming. |
|
Oozie |
A Hadoop job scheduler. |
|
Pig |
A platform for manipulating data stored in HDFS that includes a compiler for MapReduce programs and a high-level language called Pig Latin. It provides a way to perform data extractions, transformations and loading, and basic analysis without having to write MapReduce programs. |
|
Solr |
A scalable search tool that includes indexing, reliability, central configuration, failover and recovery. |
|
Spark |
An open-source cluster computing framework with in-memory analytics. |
|
Sqoop |
A connection and transfer mechanism that moves data between Hadoop and relational databases. |
|
Zookeeper |
An application that coordinates distributed processing. |
Commercial Hadoop distributions
Open-source software is created and maintained by a network of developers from around the world. It's free to download, use and contribute to, though more and more commercial versions of Hadoop are becoming available (these are often called "distros.") With distributions from software vendors, you pay for their version of the Hadoop framework and receive additional capabilities related to security, governance, SQL, and management/administration consoles, as well as training, documentation and other services. Popular distros include Cloudera, Hortonworks, MapR, IBM BigInsights and PivotalHD.
It is a comprehensive Hadoop Big Data training course designed by industry experts considering current industry job requirements to provide in-depth learning on big data and Hadoop Modules. This is an industry recognized Big Data certification training course that is a combination of the training courses in Hadoop developer, Hadoop administrator, Hadoop testing, and analytics. This Cloudera Hadoop training will prepare you to clear big data certification
1. Master fundamentals of Hadoop 2.7 and YARN and write applications using them
2. Setting up Pseudo node and Multi node cluster on Amazon EC2
3. Master HDFS, MapReduce, Hive, Pig, Oozie, Sqoop, Flume, Zookeeper, HBase
4. Learn Spark, Spark RDD, Graphx, MLlib writing Spark applications
5. Master Hadoop administration activities like cluster managing, monitoring, administration and troubleshooting
6. Configuring ETL tools like Pentaho/Talend to work with MapReduce, Hive, Pig, etc
7. Detailed understanding of Big Data analytics
8. Hadoop testing applications using MR Unit and other automation tools.
9. Work with Avro data formats
10. Practice real-life projects using Hadoop and Apache Spark
11. Be equipped to clear Big Data Hadoop Certification.
1. Programming Developers and System Administrators
2. Experienced working professionals , Project managers
3. Big DataHadoop Developers eager to learn other verticals like Testing, Analytics, Administration
4. Mainframe Professionals, Architects & Testing Professionals
5. Business Intelligence, Data warehousing and Analytics Professionals
6. Graduates, undergraduates eager to learn the latest Big Data technology can take this Big Data Hadoop Certification online training
There is no pre-requisite to take this Big data training and to master Hadoop. But basics of UNIX, SQL and java would be good.At Petaa-Bytes, we provide complimentary unix and Java course with our Big Data certification training to brush-up the required skills so that you are good on your Hadoop learning path
The post Hadoop Training appeared first on Petaa Bytes.
]]>The post Introduction to PL/SQL appeared first on Petaa Bytes.
]]>The post Introduction to PL/SQL appeared first on Petaa Bytes.
]]>The post Declaring PL/SQL Variables appeared first on Petaa Bytes.
]]>The post Declaring PL/SQL Variables appeared first on Petaa Bytes.
]]>The post Writing Executive Statements appeared first on Petaa Bytes.
]]>The post Writing Executive Statements appeared first on Petaa Bytes.
]]>The post Interacting with the Oracle Database Server appeared first on Petaa Bytes.
]]>The post Interacting with the Oracle Database Server appeared first on Petaa Bytes.
]]>The post Writing Control Statement appeared first on Petaa Bytes.
]]>The post Writing Control Statement appeared first on Petaa Bytes.
]]>The post Working with Composite Data Types appeared first on Petaa Bytes.
]]>The post Working with Composite Data Types appeared first on Petaa Bytes.
]]>The post Using Explicit Cursors appeared first on Petaa Bytes.
]]>The post Using Explicit Cursors appeared first on Petaa Bytes.
]]>The post Handling Exceptions appeared first on Petaa Bytes.
]]>The post Handling Exceptions appeared first on Petaa Bytes.
]]>The post Creating Stored Procedures appeared first on Petaa Bytes.
]]>The post Creating Stored Procedures appeared first on Petaa Bytes.
]]>The post Creating Stored Functions appeared first on Petaa Bytes.
]]>The post Creating Stored Functions appeared first on Petaa Bytes.
]]>The post Creating Packages appeared first on Petaa Bytes.
]]>The post Creating Packages appeared first on Petaa Bytes.
]]>The post Using Oracle-Supplied Packages in Application Development appeared first on Petaa Bytes.
]]>The post Using Oracle-Supplied Packages in Application Development appeared first on Petaa Bytes.
]]>The post Dynamic SQL and Metadata appeared first on Petaa Bytes.
]]>The post Dynamic SQL and Metadata appeared first on Petaa Bytes.
]]>The post Design Considerations for PL/SQL Code appeared first on Petaa Bytes.
]]>The post Design Considerations for PL/SQL Code appeared first on Petaa Bytes.
]]>The post Managing Dependencies appeared first on Petaa Bytes.
]]>The post Managing Dependencies appeared first on Petaa Bytes.
]]>The post Manipulating Large Objects appeared first on Petaa Bytes.
]]>The post Manipulating Large Objects appeared first on Petaa Bytes.
]]>The post Creating Triggers appeared first on Petaa Bytes.
]]>The post Creating Triggers appeared first on Petaa Bytes.
]]>The post Application for Triggers appeared first on Petaa Bytes.
]]>The post Application for Triggers appeared first on Petaa Bytes.
]]>